算法详解 - 重链剖分
简介
重链剖分,也被称为树链剖分,一般的,OIer 口中的树链剖分就是指重链剖分。今天我们就来一起学习重链剖分。
概念
重儿子
既然是重链剖分,那么我们就要理解什么是重。我们定义一个点的子节点中子树最大的点为这个点的重儿子。我们可以通过下面的一个例子来理解:
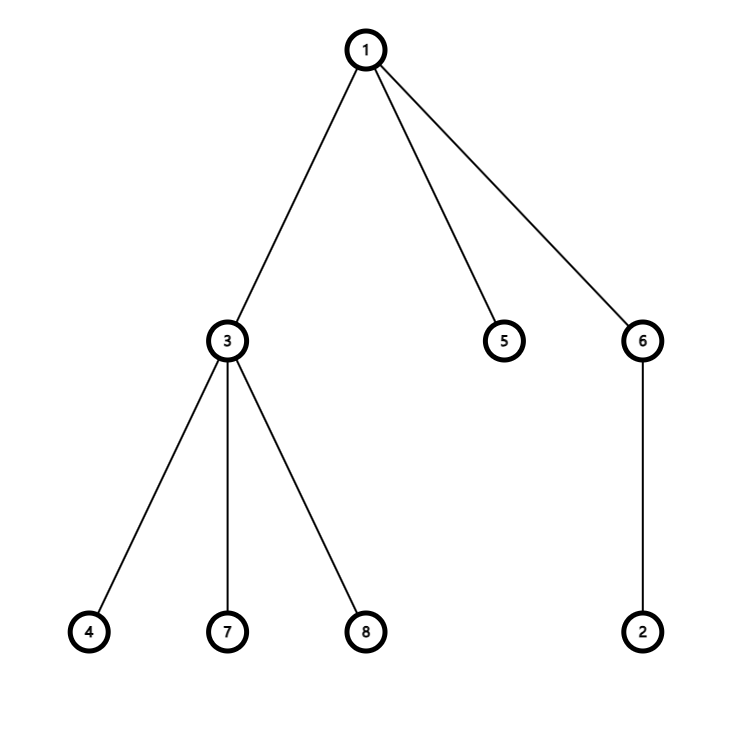
其中,节点 \(1\) 的子节点有三个,分别是 \(3,\,5,\,6\),它们的子树大小分别是 \(4,\,1,\,2\),于是我们按照定义可以得到节点 \(1\) 的重儿子就是子树大小为 \(4\) 的节点 \(3\)。
重链
顾名思义,重链就是重儿子所连成的链,举个例子:
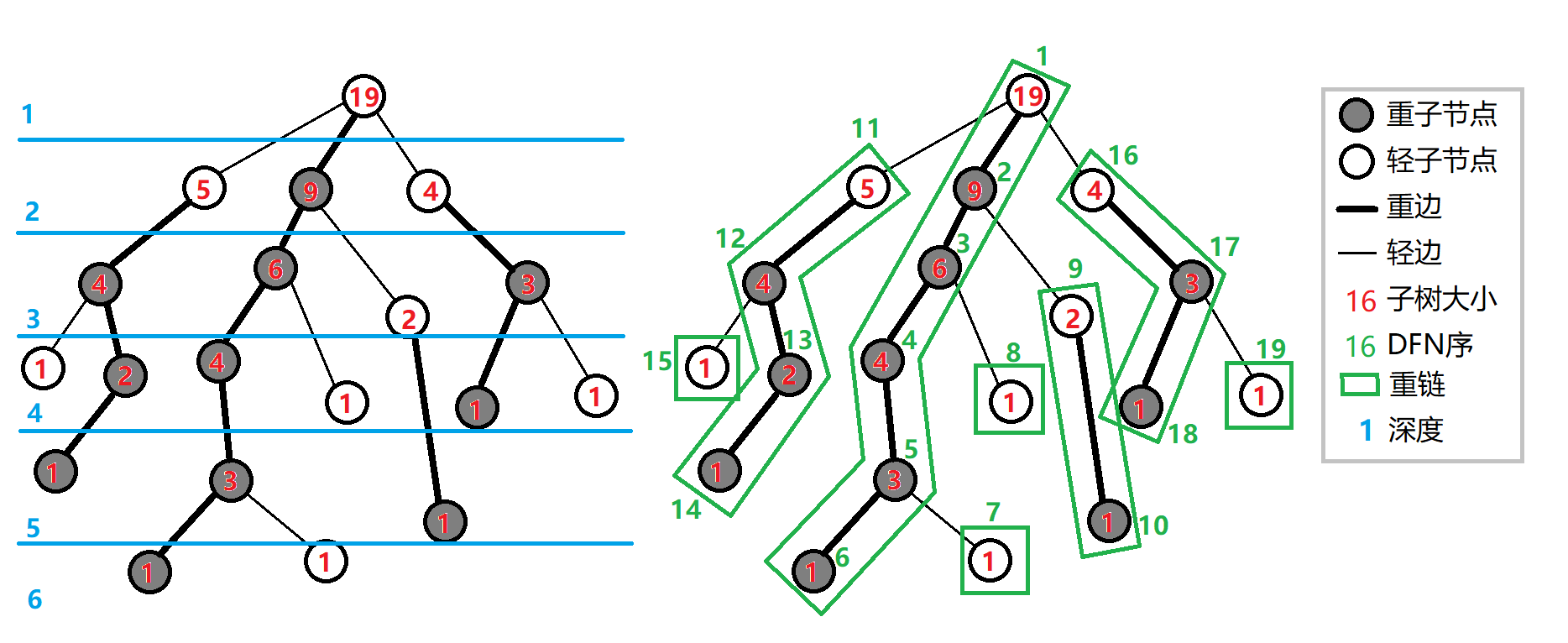
其中深色的点就是重儿子,绿色方框框起来的就是一条条重链。
实现
顾名思义,重链剖分就是把重链找出来。于是我们考虑如何找出来重链。一种很显然的方式就是进行 DFS,我们需要执行两次 DFS。
- 在第一次 DFS 中,我们记录出每个节点的子树大小、重儿子、深度的信息。
- 第二次,我们按照重儿子优先的顺序再次遍历树,然后记录 DFN 序(也就是 DFS 访问时的时间戳)以及每一条重链的重链头。
由此我们获得的这棵树的 DFN 值,但是这有什么用呢?我们需要先来了解一些性质。
性质
- 每一个树上的节点属于且仅属于一条重链。这个其实也很好证明。由于每一个点只有一个重儿子,因此连接这个点的重链有且仅有一条。因此我们会发现重链可以把任意一棵树完全剖分(即将一棵树完全的分为若干条链)。
- 重链内的 DFN 是连续的。这个性质很容易得到,因为我们是重度优先搜索的,因此我们必然优先搜索同一条重链上的点,于是我们同一条重链上的 DFN 就是连续的。
- 一棵子树内的 DFN 是连续的。这个是 DFS 决定的,很好理解。你可以发现,DFS 总是遍历完当前子树再去做其他考虑,于是很容易就发现同一棵子树内的 DFN 是连续的。
- 树上的路径可以被拆分为不超过 \(\log_2n\) 条重链。这个性质对于我们的复杂度分析是十分有用的。同时这个性质也是非常容易得到的。当我们遍历的时候,总是将子树分为重子树和其余节点,因此子树的大小总是被除以 \(2\)。
使用
我们会发现,重链剖分后 DFN 的连续性是十分可用的。这就给我们使用区间数据结构的机会了。通过这个性质,我们可以在树上借助 DFN 维护一棵线段树。线段树的下标就是对应节点的 DFN 值。
于是我们就可以动态维护一些树上的区间和、区间方差、最大最小值之类的东西,同时顺手求出 LCA,复杂度还和倍增法差距不大。
例题
思路
我们将引入一道例题以加深你对重链剖分的理解。
动态维护树上的区间和。
我们看到题目给出软件包的依赖关系,很容易的就自然联想到图论上,对吧?对吧?然后我们再观察一下,发现题目刚好描述了一棵树。
我们把样例的树建出来,是这样的:
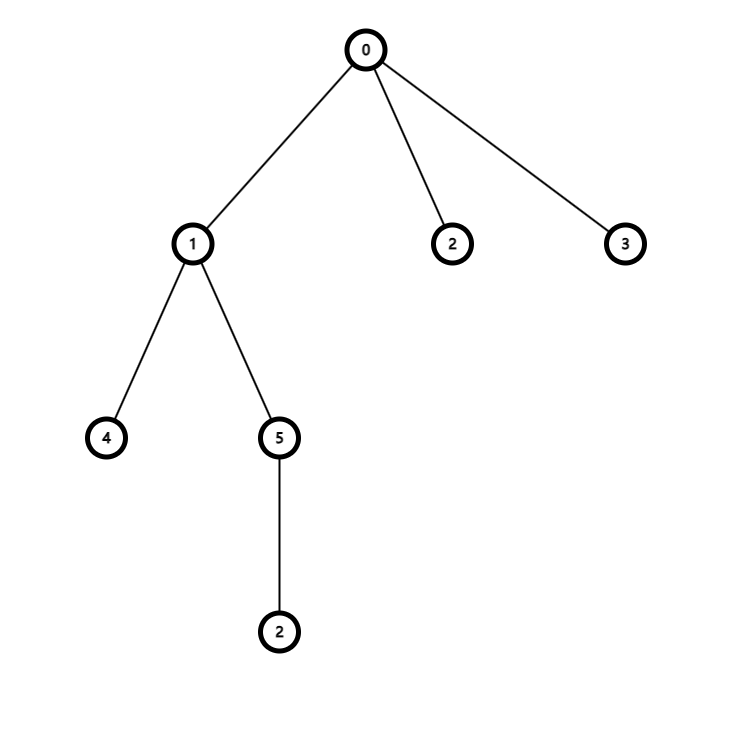
我们设每个点的初始权值为 \(0\),也就是未安装。
- 当安装软件包的时候,我们将该软件包到根软件包的路径上的软件包全部安装,也就是全部设置为 \(1\),并统计有多少个原本不是 \(1\) 的,计入答案,输出。
- 当卸载软件包时,我们卸载这个软件包及其所在子树上的软件包,也就是把整个子树都设为 \(0\),然后统计原来有多少个 \(1\),输出即可。
实现
我们首先用两个 DFS 预处理出我们所需的信息:深度、子树大小、重儿子、DFN 序、重链头等信息。
1 | |
进行预处理后,我们开始建树。
首先简单写一下线段树的两个基本操作。
1 | |
然后我们写一个区间修改操作。
1 | |
然后类似地写一个区间查询。
1 | |
然后我们来看一下如何遍历某一个节点到 \(1\) 节点的路径,我们考虑类似 LCA 的方法往上跳,实现如下:
1 | |
当然在我们的题目中,\(y\) 始终不变,于是乎我们可以将这段代码简化一下,就像这样(加上了修改的过程,注意先查再改):
1 | |
此时我们的 ans
就是所要求的需要额外安装的节点数量啦。
然后我们来考虑如何更新子树上的东西。我们在刚刚提到了一个性质:一棵子树内的 DFN 是连续的,于是利用这个性质,我们可以很容易的得出区间。假设子树的根节点是 \(u\),那么这个子树 DFN 序最小的必然就是根节点了,又由于子树内下标连续,因此我们可以计算出最后一个属于子树的下标是 \(dfn_u + sz_u - 1\)(根节点 DFN + 字数大小 - 1)。这样我们就可以很快的统计出答案啦!
1 | |
最后贴一下整体的代码,希望你喜欢这篇文章呀:
1 | |